Practical introduction to relational databases
Create table
Let's talk about the parts of a table:
- schema, and name of the table
- rows, to hold each record
- columns that specify what kind of data we're holding for a record, and what the size of that data can be
- indexes, and constraints, to enable faster lookup of data, or to enforce some form of format that our data can have
To create a table, we need to specify each of these parts. For our purposes and in the context of the fake ecommerce site you have cloned, we're going to start with the products table.
If you look in the codebase of the ecommerce site, a single product looks like this:
{
name: "widgetinator 9000",
price: 1337,
id: "w90sss",
sku: "w90sss-433",
}
From that we know we need 4 columns for the 4 pieces of data we need to store:
- an id column for the id
- a text column for the name
- another text or varchar column for the sku (stock keeping unit)
- and a number to store the price in cents (our fake ecommerce store is based on USD)
Postgres, as most relational databases, has the concept of data types. They serve three distinct functions:
- first, they help you restrict the kind of data to hold. A timestamp column can't hold text. An integer column also can't hold text. A boolean column can't hold a timestamp.
- Second, it helps with keeping the size of the database in control. If you know that a piece of data is only ever going to be a value lower than 32768, then there's no reason to use a
bigint column type, as that's just wasting space - third, it helps the database engine with sorting the data. Integers are a lot easier and faster to sort and find by than free text.
There is no difference between text and varchar column types in postgres if varchar has no length specifier. See the Postgres version 13 documentation on their data types. They are both "variable-length character strings."
If you looked at the postgres data types link already, you might have noticed that there are a few different variations on numeric data types.
There are three different integer types, smallint, integer, and bigint. Documentation suggests to use integer, unless you're running out of space and can fit the data in the smallint column, or if the values you want to store do not fit in the range integer provides.
For the sake of example here, we're going to use smallint, as it's good for the range -32768 to +32767, and none of our products are going to cost more than $327, and we'll ignore negative numbers for now.
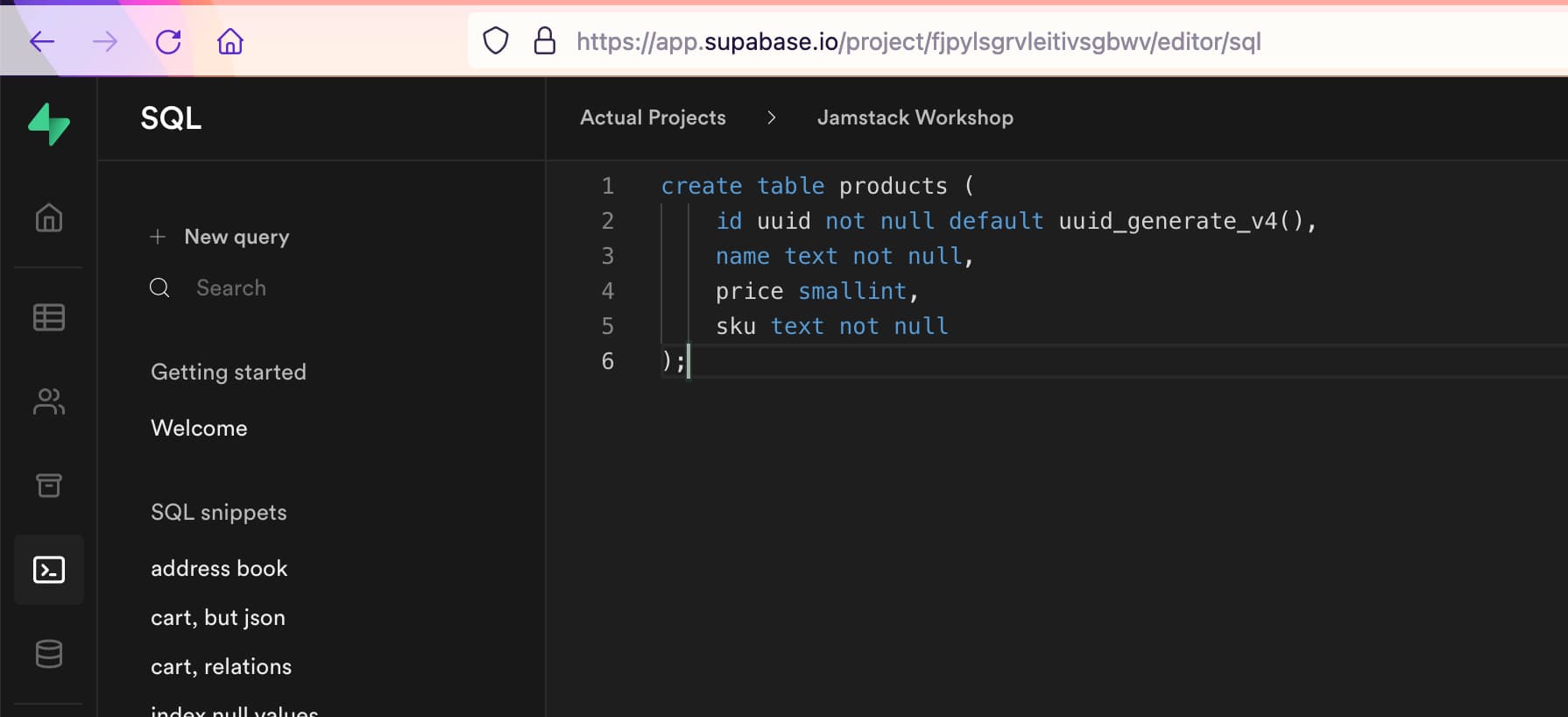
Here's the code to create a new products table that we can use:
create table products (
id uuid not null default uuid_generate_v4(),
name text not null,
price smallint,
sku text not null
);
To colour code what part does what, here's an image:

In short, no. As a convention it can make life easier to visually distinguish which parts are SQL grammar (ie modifier words, etc), and which parts are given names that we provided the database with, but the part of the database that takes our query and makes sense of it will not care if the control parts are in all caps, or not.
The above query looks like this with the control words in all caps:
CREATE TABLE products (
id UUID NOT NULL DEFAULT uuid_generate_v4(),
name TEXT NOT NULL,
price SMALLINT,
sku TEXT NOT NULL
);
With that, we're now ready to run this query.
In supabase, go to the SQL window. It has an icon of a >_ with a border around it. See the image to help you.
In that page, click on the + New query link at the top of the new sidebar, and copy paste the create table command into the query window on the right. It should look like this:
Once that's there, hit cmd+enter / ctrl+enter (I don't actually know the keyboard shortcut on Windows), or click the Run button in the bottom right corner of the query window. You should see the following in the result window, below the query window:
Success. No rows returned
With that, you're ready to move on to the next page, dropping tables!